








Shifting to a ‘paperless office’ marks an important jump in any organization’s journey towards the next level of performance. And more often than not, it is the DMS (Document Management System) that lies at the heart of this transition.
Amongst other things, the ‘operation’ involves digitising paper files by first scanning them, and subsequently storing them. The crucial consideration here is that they need to be stored in a format that is “search-friendly”(apart from being compact, convenient and editable), so that they can be retrieved with minimum fuss and in minimum time when needed.
OCR (Optical Character Recognition) is the technology that does this job. Typically, an OCR optimises scanned documents for search by turning printed matter into fully searchable digital assets that let you access and retrieve any word or phrase (across the document) instantaneously.
Before adding – or checking for – the OCR in your DMS, here are 3 important aspects you need to bear in mind.
The first is accuracy. In reality, digital scans can be far from perfect. And given the potential damage, the margin of error is zero. Go for an OCR with a sophisticated algorithm, a robust and reliable ‘engine’, and comprehensive support for your specific scenario.
Next, you must weigh in the conversion speed of the OCR engine. Choose an OCR that offers high speed processing with minimal system requirements in terms of CPU speed, RAM and others.
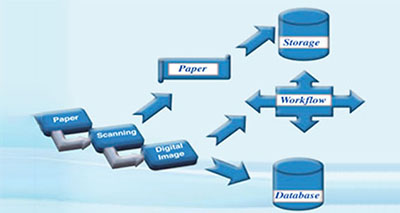
Thirdly, the output format that you need – PDF, text (word) file, image or any other – should play a deciding role in finalising the OCR specs.
In case your DMS software does not carry the required OCR features, there are various third party tools in the market that can help you upgrade easily with scalable OCRfeatures,including some variants which allow for integrating such third party OCR engines via a web API to your DMS. This kind of integration can help you leverage the benefits organisation-wide quickly and smoothly.


